Motivation

Figure 1.
Unlike prior works which attempt to predict the next state for learning mapping functions, which is reported to be prone to compounding errors,
we aim to align the effect of the transitions across domains.
For instance, the effect of transition in Domain A is moving the gripper from the left side to the right side.
The effect of the translated transition in the Domain B is expected to move the gripper from the left side to the right side as well.
Method Overview

Figure 2. We show the main terminologies from both the source domain and the target domains, and the main objective in our method.
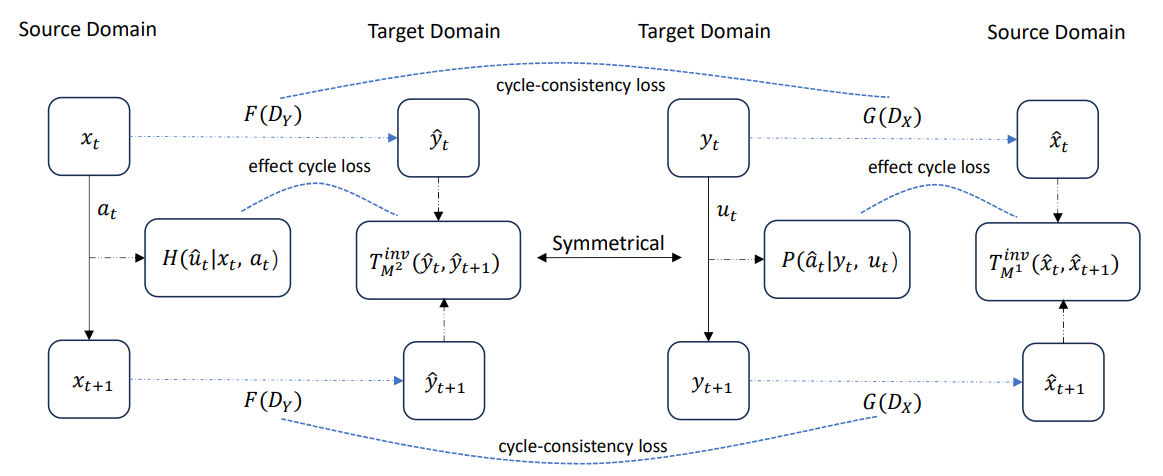
Figure 3. The training structure. We apply the same objectives of learning mapping functions from source domains to target domains to learning from target domains to source domains.
We attempt to discover the translated action distribution that can lead to the same effect in the target domain as the source domain.
Experiment Results
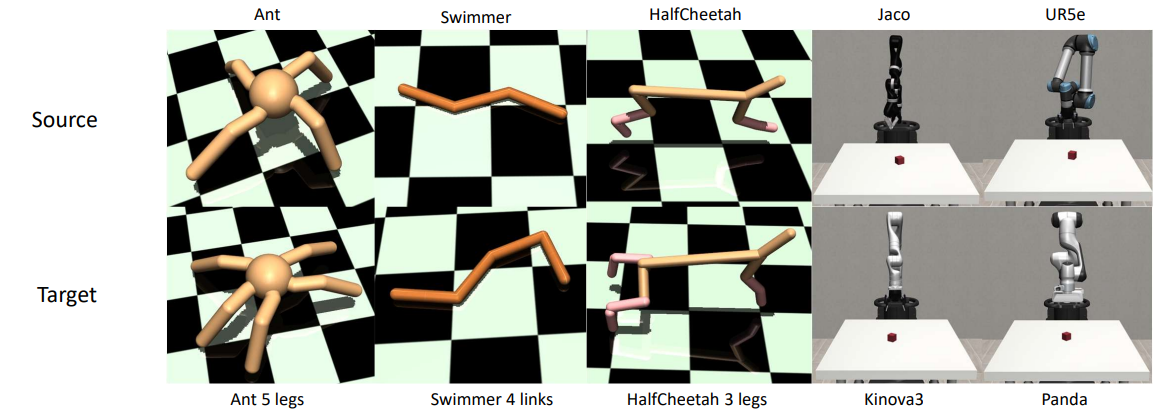
Figure 4.
Visualization of source domains and target domains. We carried out experiments on three locomotion tasks and two robotic manipulation tasks

TABLE I The performance of the transferred policy under different morphologies. (w.o. denotes without)

The behaviours of the transferred policies through the learned mapping functions.