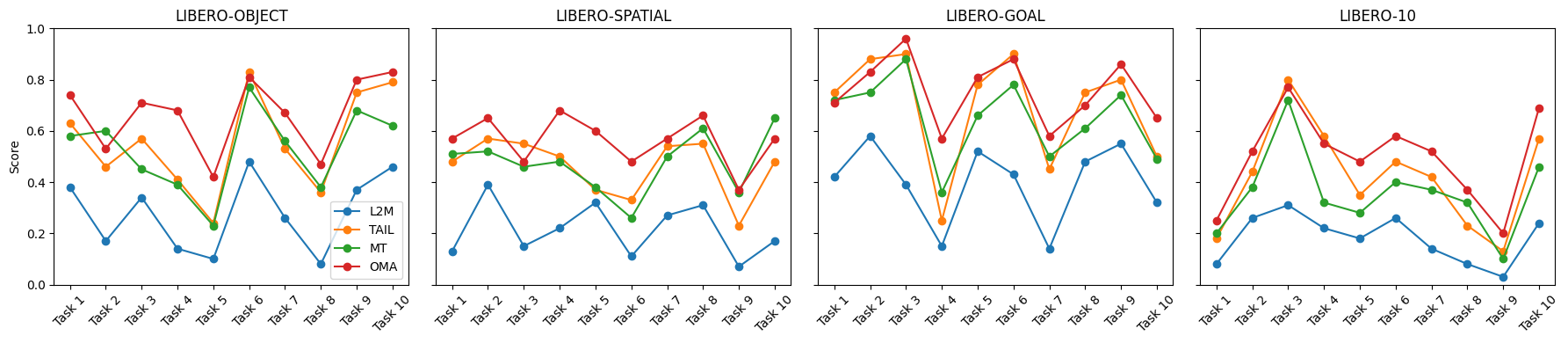
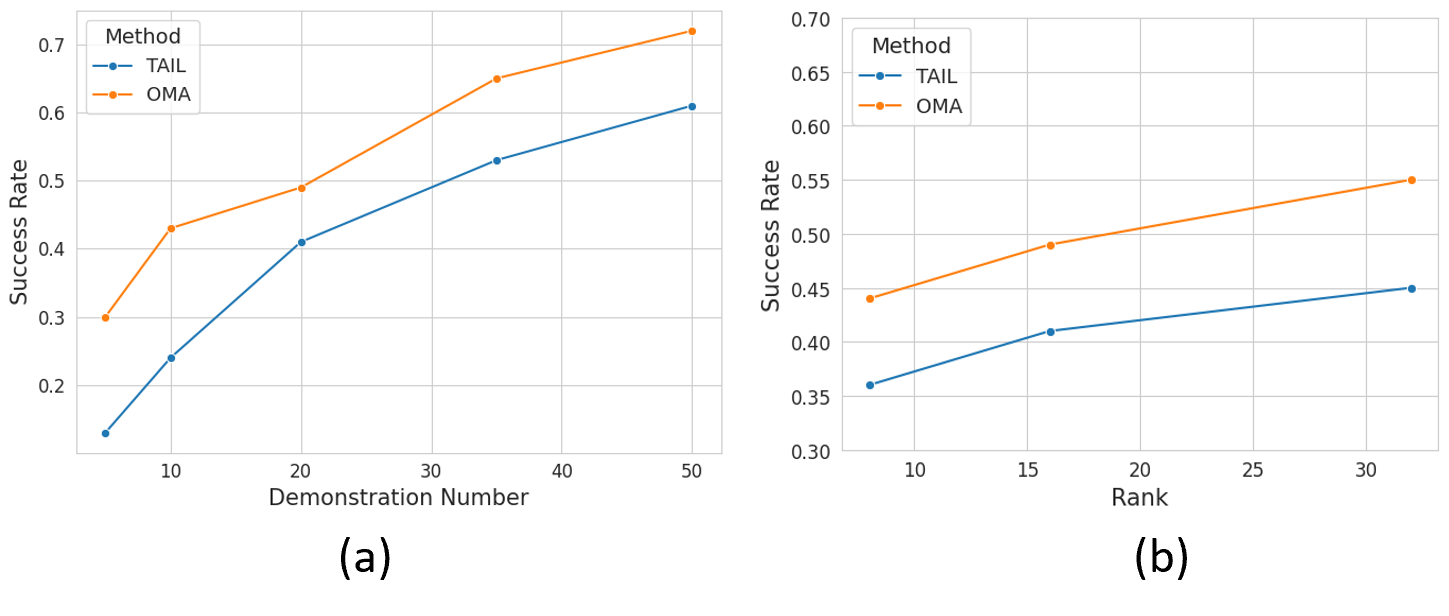
Key Results
OMA is evaluated on LIBERO continual adaptation suites and real-robot tasks with 20 demonstrations. Across simulation, OMA consistently outperforms adapter-based baselines including L2M, TAIL, and a multi-task adapter baseline. The experiments also show that OMA remains effective across different demonstration counts, LoRA ranks, and policy architectures.
+17%
Average simulation improvement over prior adapter-based baselines.
49.5%
LIBERO-10 success rate in the ablation study, above random task and support selection variants.
+19%
Average real-robot improvement over TAIL across tested demonstration settings.